Resource Identity and Semantic Extensions:
Making Sense of Ambiguity
David Booth, Ph.DSemantic Technology Conference, San Francisco
25-June-2010
Latest version: http://dbooth.org/2010/ambiguity/
Also available: PowerPoint slides
Abstract
What does a URI denote? How should its referent be determined, even in the presence of semantic extensions that affect the interpretation of an RDF graph? How should ambiguity be viewed?One view is that a given URI has no fixed referent, but may denote different things in different contexts. Another is that a URI should denote the same resource in any context. A third is that each URI should have a URI declaration that precisely delimits its interpretation. Some suggest reusing existing URIs in new contexts, while others prefer to mint new URIs and then allow owl:sameAs assertions to indicate that two URIs denote the same thing.
This presentation sheds light on these issues by: (a) explaining how ambiguity of a URI's referent fits within standard RDF semantics; (b) explaining how this ambiguity applies to the use of owl:sameAs; and (c) proposing a standard operational sequence for determining the intended referent of a URI, even in the the presence of semantic extensions.
Table of Contents
- PART 0: Myths about resource identity and RDF semantics
- Myth 1: A URI denotes only one resource
- Myth 2: RDF semantics are global
- Myth 3: Resource ambiguity is due to sloppiness
- Myth 4: Truth is absolute
- PART 1: RDF Semantics and Ambiguity
- PART 2: Constraining Ambiguity through URI Declarations
- PART 3: Determining Resource Identity
- 1. Select assertions – what graph?
- 1.a. Recursively merge ontologies and URI declarations
- 2. Apply RDF semantics and semantic extensions
- 3. Select an interpretation
- Conclusions
- Footnotes
PART 0: Myths about resource identity and RDF semantics
Before delving into our main subject it is useful to confront some widespread myths about resource identity and RDF semantics. Some of these are overt; others are more implicit in the assumptions that many in the RDF community make in the questions that they pose. The rationale for dispelling these myths will be further explained in later sections. But first, we should clarify what we mean by "resource identity".In RDF, URIs are used as names for resources, as illustrated in Figure 04-uri-question-resource.png below. This use is complementary to a URI's potential use as a locator by which a document may be retrieved. A "resource" may be anything -- a person, a protein, a medication, a concept, etc. In essence, the class of resources is the universal class of things -- an infinite class. Because a URI can denote any resource, a central question in RDF semantics is: What resource does a given URI denote? Which of the potentially infinitely many? This is the question of resource identity -- the determination of which resource a URI denotes.
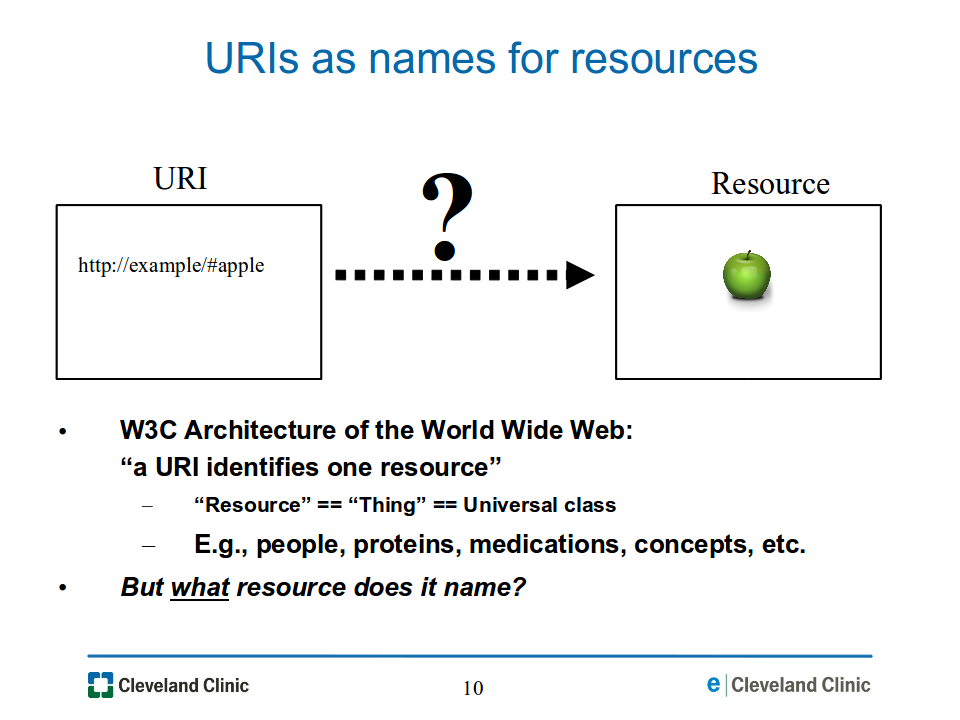
Figure
04-uri-question-resource.png:
A URI is used as a name for a resource.
Myth 1: A URI denotes only one resource
A key principle of the web is that URIs have global scope: they define a universal space of names that allows them to have the same meaning regardless of context. Since URIs are used as names, the premise is that a name denotes one resource.
Reality: While this is true as an important guiding principle and a simplified ideal, if we dig into the semantics of RDF we discover that there are significant limitations to this idea. While it is true for one interpretation of one RDF graph, different interpretations of the same graph may map the same URI to different resources, and different graphs may permit different interpretations. This will be further explained later.
Myth 2: RDF semantics are global
This is really a variation of Myth #1. The implicit assumption is that there is essentially one giant RDF graph, and the semantics of a particular RDF statement must be universally consistent with this giant graph. For example, there has recently been concern expressed that owl:sameAs makes too strong a semantic commitment, and perhaps a weaker version is needed. In one sense this is a purely practical concern that arises when multiple graphs are merged. But in another sense it reflects an implicit assumption that one should be able to freely combine sets of RDF statements, because in essence they are all part of the same giant, virtual RDF graph.Reality: While the rules for RDF semantics are globally standardized in the W3C RDF Semantics specification, they only specify the semantics of a given RDF graph: you first must decide which graph you wish to analyze, and then the RDF Semantics specification tells you the semantics of that graph. But there are many RDF graphs -- a potentially infinite number. Indeed, any set of RDF statements can be considered an RDF graph whose semantics are to be analyzed. Even though the same URI or RDF statement may appear in more than one RDF graph, it does not necessarily have the same "meaning": the semantics may differ, because the semantics are defined in terms of the graph. Specifically, a URI may denote different resources in different graphs, as illustrated later.
Myth 3: Resource ambiguity is due to sloppiness
The assumption is that if you are precise enough in defining exactly what resource your URI is intended to denote, then its identity can be uniquely determined by others who use your URI.Reality: In all except vanishingly few cases -- mathematical abstractions, for example -- ambiguity is unavoidable, no matter how precise you try to be. The essential reason is that it is always possible to make ever finer resource distinctions. For example, one might mint a URI for David Booth, the author of this paper: http://thing-described-by.org/?http://dbooth.org/2005/dbooth/ , and one might initially assume that this URI is ambiguous, and for many purposes it may be. But other applications may use very specific notions of what constitutes a person. Is this referring to David Booth as a legal entity? As a physical body? At what point in time, given that our cells regenerate continuously? These are all distinctions that are necessary to some applications but not to others. For further insight about the inherent impossibility of eliminating ambiguity, see In Defense of Ambiguity by Pat Hayes and Harry Halpin.
Myth 4: Truth is absolute
The sentiment here is that “if your RDF models the world as flat, then it is wrong”. This assumption is rooted in the idea that RDF assertions are making statements about the real world. For example, if you make an assertion involving the URI that denotes David Booth, http://thing-described-by.org/?http://dbooth.org/2005/dbooth/ , you are making an assertion about the real person.Reality: In semantic web architecture, “truth” is irrelevant. What matters is usefulness, and different applications have different needs. For example, an RDF graph that models the world as flat is obviously wrong in the sense that the real world is not flat. Nonetheless, the flat world model may be a good enough approximation for street navigation purposes, as the effects of the earth's curvature are negligible at this scale. Furthermore, a flat world model is simpler than a curved world model, and therefore more efficient to process and cheaper to build and maintain. In short, the flat world model is better for some applications, though obviously for other applications it would be completely inadequate. Furthermore, as pointed out in myth #3, nearly every description that we make is an approximation that holds only within a range of applications or contexts. Hence, whether or not an RDF graph accurately models the world in some absolute sense is irrelevant if it useful to applications.
PART 1: RDF Semantics and Ambiguity
This section examines some of the logical consequences of standard RDF semantics, as they pertain to ambiguity of resource identity.The RDF Semantics specification defines the semantics of a given RDF graph in terms of the possible interpretations for that graph:
"The
basic intuition of model-theoretic semantics is that asserting a
sentence makes a claim about the world . . . . [An] assertion
amounts to stating a constraint on the possible ways the world might
be. . . . [There] is no presumption here that any assertion contains
enough information to specify a single unique interpretation. It is
usually impossible to assert enough in any language to completely
constrain the interpretations to a single possible world, so there is
no such thing as 'the' unique interpretation of an RDF graph. In
general, the larger an RDF graph is - the more it says about the world
- then the smaller the set of interpretations that an assertion of the graph allows to be true - the
fewer the ways the world could be, while making the asserted graph true
of it."
An interpretation provides a mapping from URIs to resources. For the given RDF graph, it maps each URI to one resource, as illustrated in Figure 05-interpretations.png below.
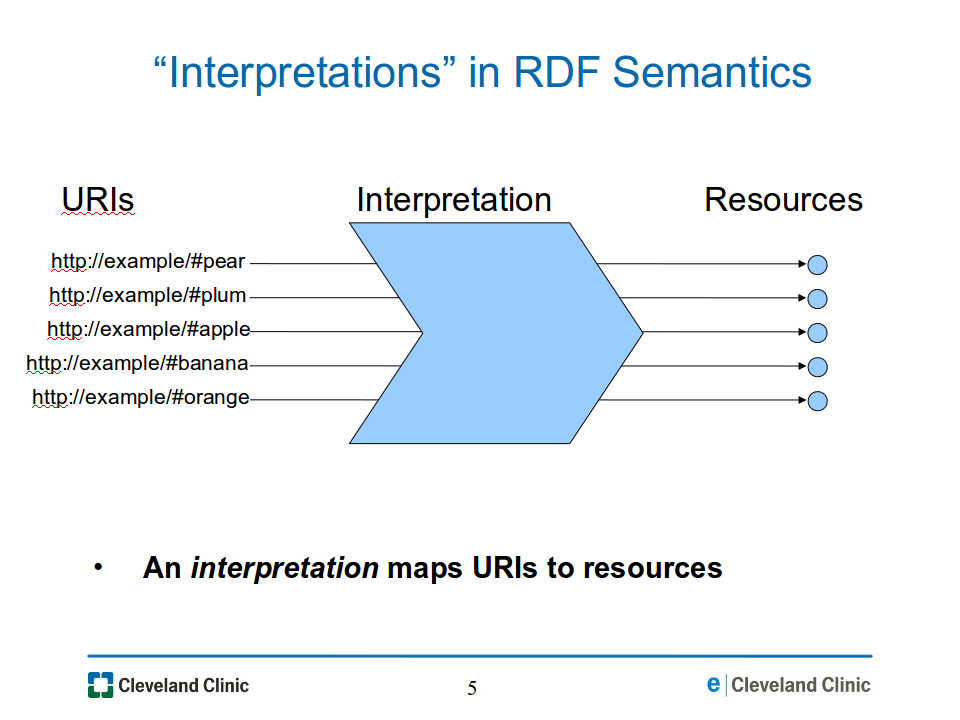
Figure
05-interpretations.png:
An interpretation maps each
URI to one resource.
For a particular URI such as http://example/#apple, an interpretation maps that URI to one particular resource, as illustrated in Figure 06-interp-one-uri.png.
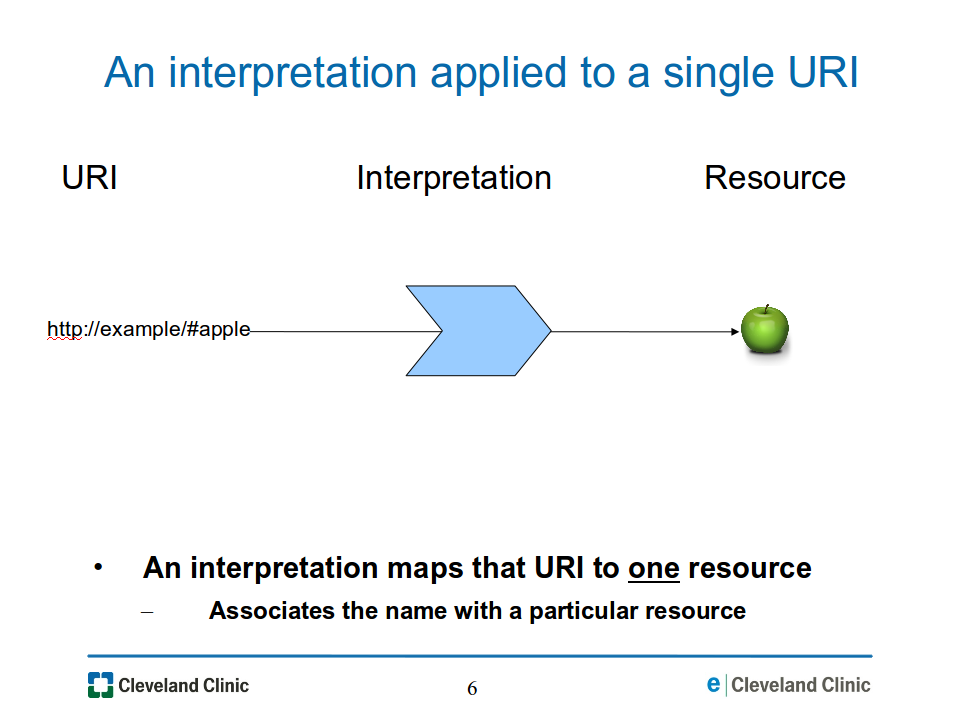
Figure
06-interp-one-uri.png: An interpretation maps one URI to one
resource.
However, since in general the RDF semantics does not uniquely constrain the interpretations that are possible for a given graph, different interpretations may map that same URI to different resources, as illustrated in Figure 07-multiple-interp.png.
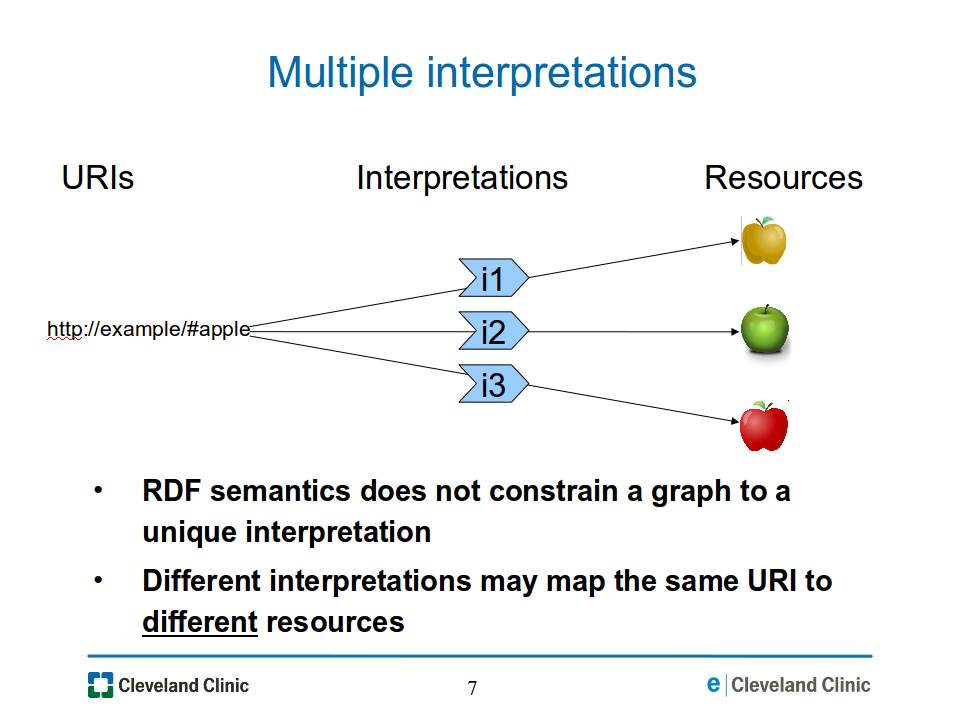
Figure
07-multiple-interp.png: Multiple interpretations may map the
same URI to different resources.
In fact, a given graph may permit many interpretations -- potentially infinitely many. This means that a URI in a given graph may be mapped to many different resources, as illustrated in Figure 08-many-interp.png.
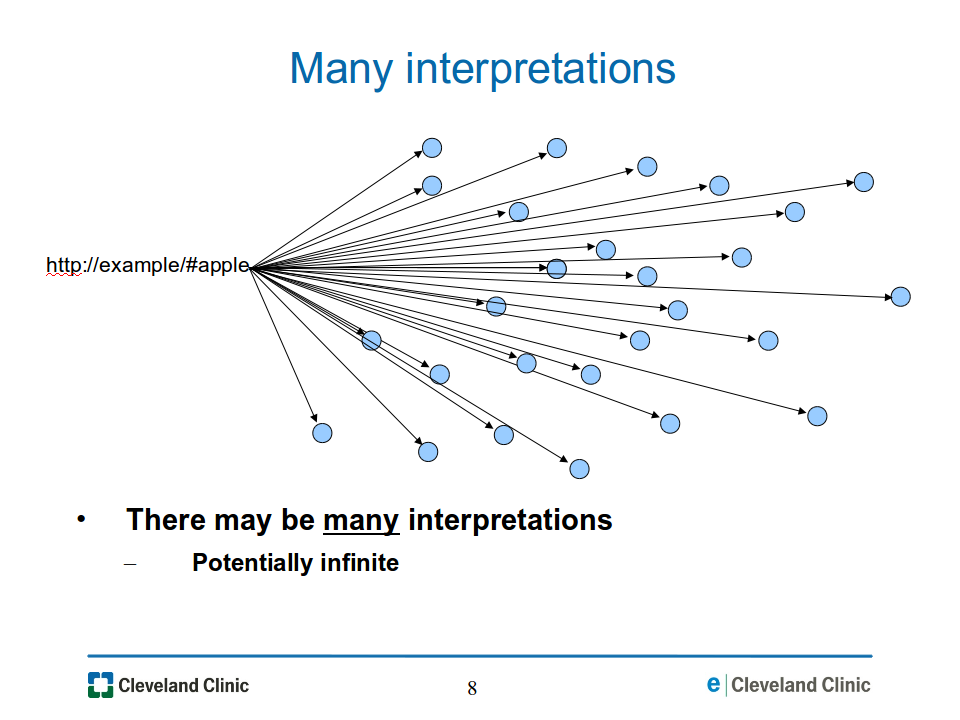
Figure
08-many-interp.png: There may be many interpretations for an RDF
graph, mapping the same URI to many resources.
Rules in the RDF semantics precisely constrain the possible interpretations for a given graph, so although the set of resources to which a URI maps may be large or even infinite, it is constrained to a particular set, as illustrated in Figure 09-constraining-interp.png. (This is a slight simplification to facilitate visualization. For further explanation and clarification, see footnote[1].)
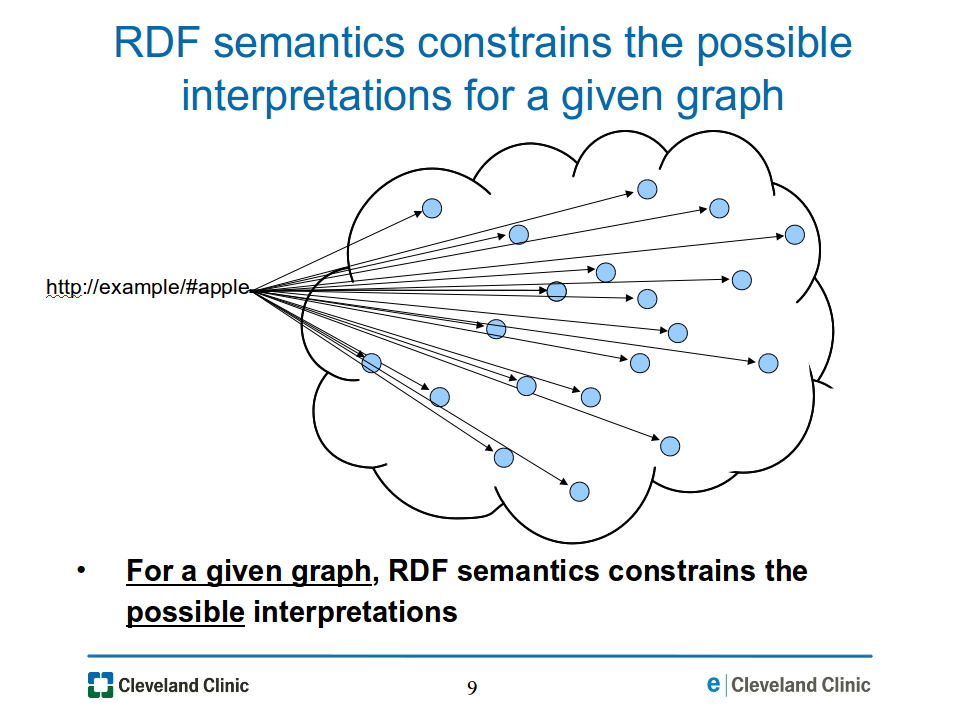
Figure
09-constraining-interp.png: The RDF semantics constrains the set
of possible interpretations of a given graph, thus constraining the set
of resources to which a URI may map.
The effect of adding assertions to an RDF graph is that the set of possible interpretations is monotonically reduced. Thus, the corresponding set of resources to which a URI may map is consequently reduced, as illustrated in Figure 10a-reducing-interp.png. This is what happens when two RDF graphs are merged, because the constraints of both graphs must be satisfied in the combined graph.
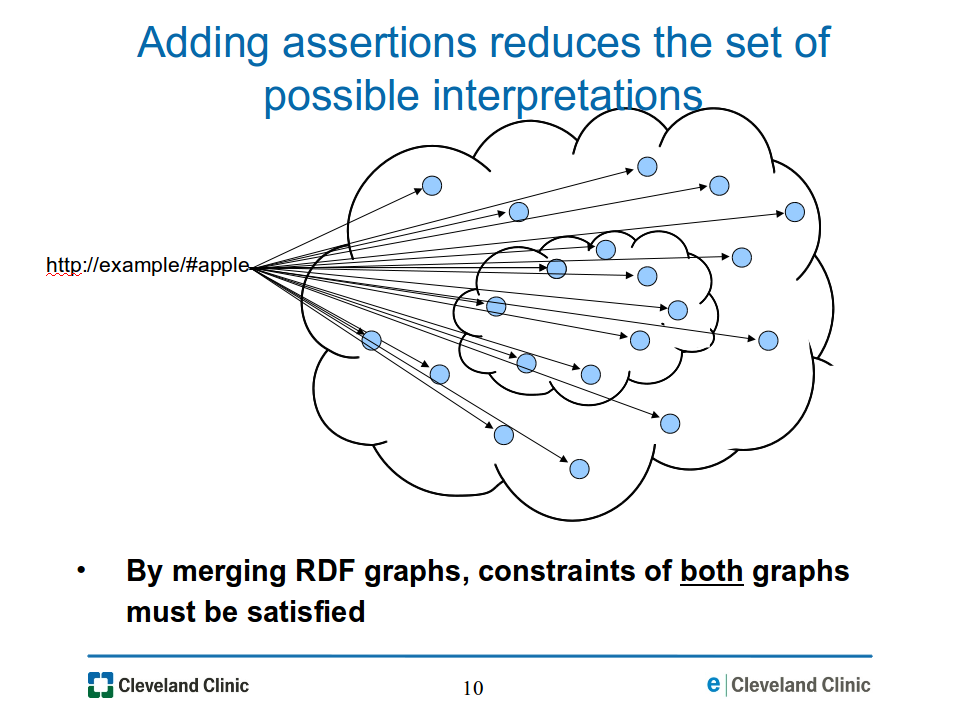
Figure
10a-reducing-interp.png: Combining RDF graphs reduces the
interpretations that are possible, thus reducing the possible resources
to which a URI in the combined graph may map.
Interpretations of a URI. We will frequently need to refer to the set of resources to which a URI may map under the RDF semantics for a given RDF graph. For convenience, we will refer to these resources as the interpretations of the URI. More precisely, the interpretations of a URI for a given RDF graph consists of the set of resources that may be mapped from that URI by all possible interpretations for that graph under the RDF semantics.
Resource ambiguity. For a given RDF graph, a URI's resource identity is ambiguous if there exists more than one possible interpretation for that URI, i.e., the possible interpretations for that graph permit the URI to be mapped to more than one resource. Although the referent of a URI is almost always ambiguous in this specific sense, this does not mean that it is useless or ambiguous to a particular application. It is relative: what is clear enough for one application may be ambiguous to another application, and we need to get used to this.
Overlapping interpretations and owl:sameAs. Interpretations of different URIs are not necessarily disjoint. They may overlap. Indeed, this is exactly what happens when an owl:sameAs assertion is included in a graph. The assertion "X owl:sameAs Y" causes the interpretations for both X and Y to be limited to the intersection of the interpretations of X and the interpretations of Y that would have held if the graph had not included the owl:sameAs assertion, as illustrated in Figure 14-effect-of-sameas.png. Finally, if the intersection is empty, then the graph cannot be satisfied: there is an inconsistency.
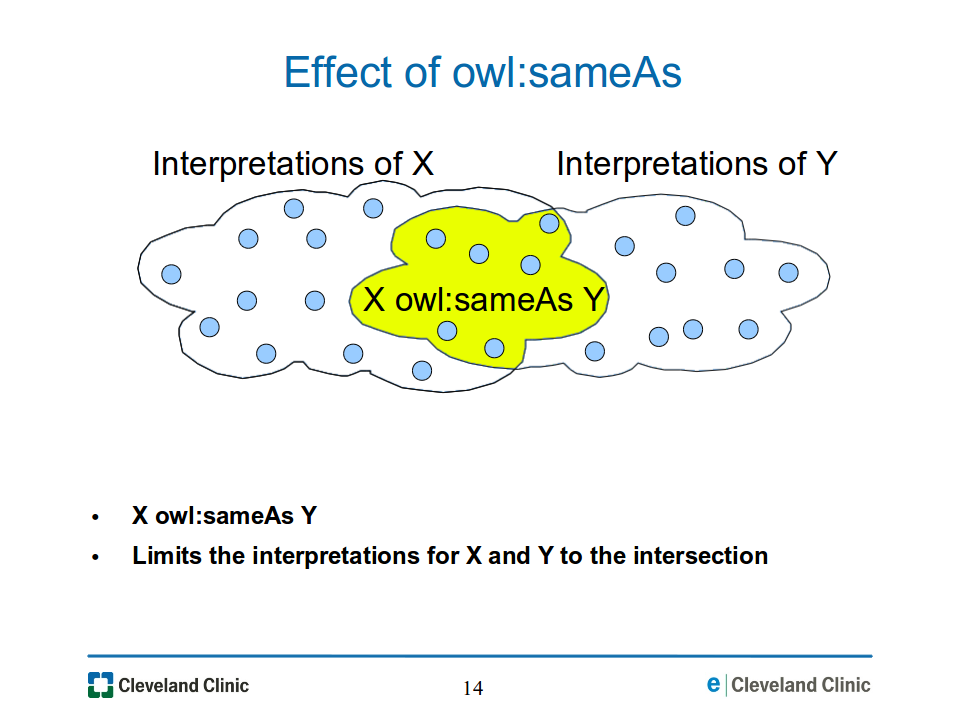
Figure
14-effect-of-sameas.png: The assertion "X owl:sameAs Y" in an
RDF graph causes the interpretations of both X and Y to be limited to
the intersction of the interpretations of X and the interpretations of
Y that would have held if the owl:sameAs assertion had not been
included in the graph.
PART 2: Constraining Ambiguity through URI
Declarations
This section proposes a standard way to constrain resource ambiguity.How should a URI owner indicate what resource his/her URI is intended to denote? Although this question is not answered in the Architecture of the World Wide Web, a best practice that has emerged in the semantic web community is to use an http URI that can be dereferenced -- perhaps indirectly -- to a document that provides this information, as described in Cool URIs for the Semantic Web. To help crystalize this practice and clarify how it should work architecturally, the term "URI declaration" was coined and described in URI Declaration in Semantic Web Architecture.
A URI declaration provides a definition for a resource denoted by a URI, by providing a set of core assertions that should be used to constrain the possible interpretations for that URI. As described in Cool URIs for the Semantic Web, the URI owner should make the URI declaration (indirectly) available by dereferencing that URI. Thereafter, RDF statement authors and RDF consumers should use the core assertions in that the URI declaration to constrain the interpretations of that URI. This provides an easy way for both RDF statement authors and RDF consumers to know what definition to use for the URI's resource. It permits all users of the URI to share the same definition, which helps to stablize the meaning and prevent semantic drift.
Although the URI declaration provides a common definition for a URI's denoted resource, in general the identity of that resource is not uniquely determined, as previously explained: there will still be multiple interpretations for that URI. However, the set of interpretations is precisely bounded: in any RDF graph that uses that URI (with the core assertions of the URI's declaration) the interpretations for that URI will be bounded by the set of interpretations for that URI that arise from the core assertions of the URI declaration, as illustrated in Figure 18-bounding-interp.png.
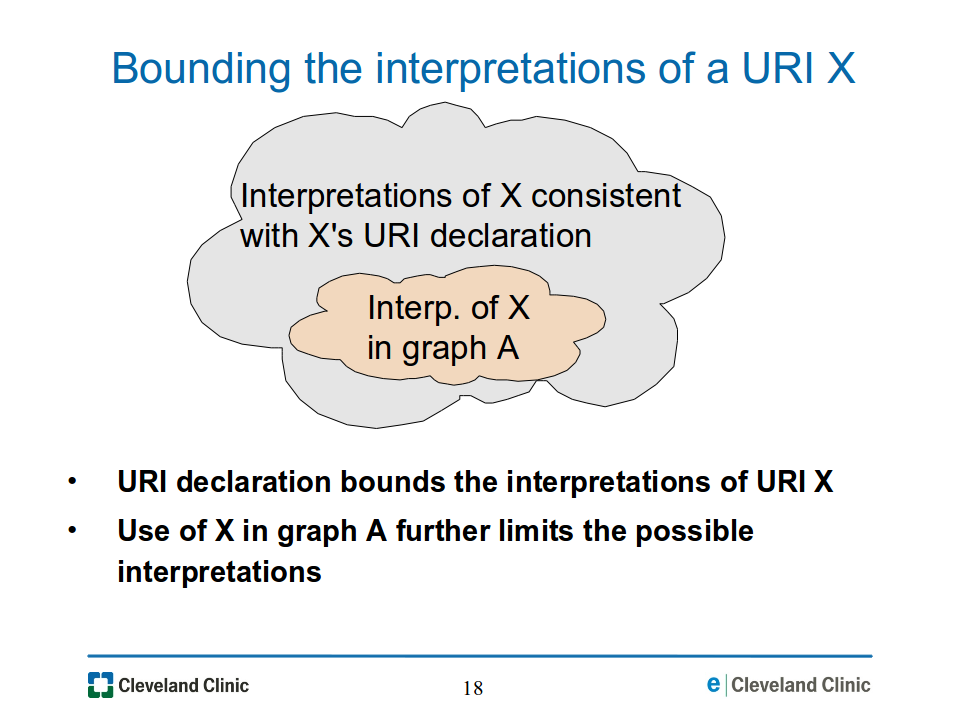
Figure
18-bounding-interp.png: A URI declaration precisely bounds the
interpretations of a URI. For a given RDF graph, the
interpretations of that URI falls within those bounds.
Inconsistent merged graphs. Suppose a URI X is used in three RDF graphs A, B and C. For each of these graphs, the interpretations of X forms a different set of possible resources, and these sets may overlap, as illustrated in Figure 26-inconsistent-graphs.png. Although the merge of graphs A and B may be consistent -- resulting in the interpretations of X being limited to the intersection of the interpretations of X in each graph separately -- and the merge of graphs B and C may be consistent, the merge of graphs A and C (or of A, B and C) may not be consistent: there may be no possible interpretations for X that are consistent with the combined graph, as illustrated in Figure 26-inconsistent-graphs.png.
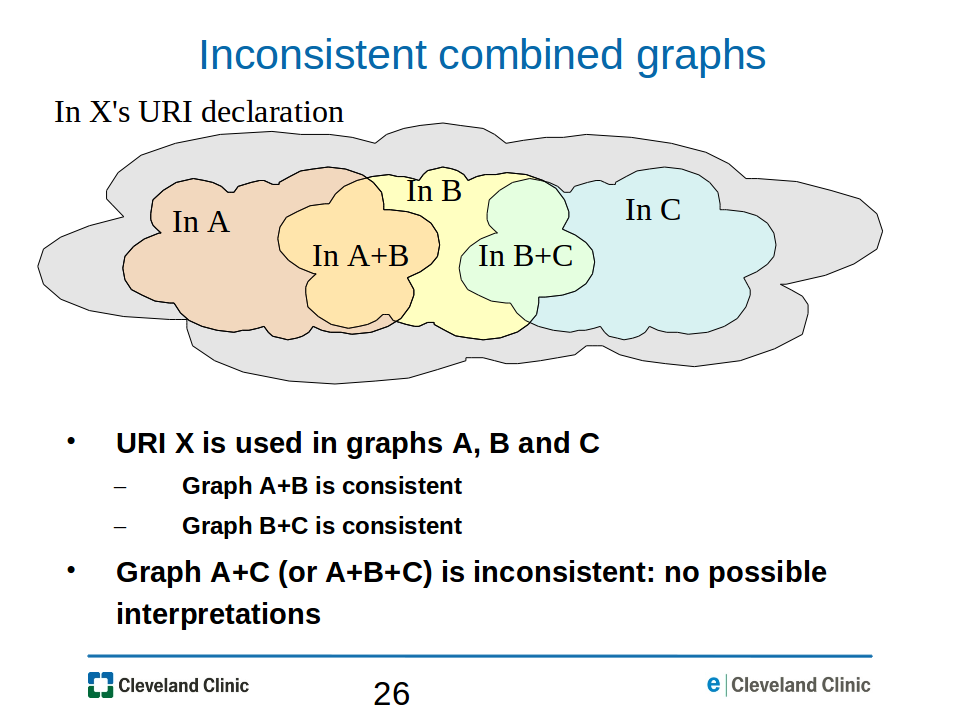
Figure
26-inconsistent-graphs.png: The merge of graphs A and B may be
consistent, and the merge of graphs B and C may be consistent, but the
merge of graphs A and C (or of A,
B and C) may be inconsistent. Thus, the interpretations of a URI X are
limited to one set of resources in graph A, and
limited to a different -- and disjoint -- set of resources in graph C.
This is a common practical problem that arises when multiple RDF graphs are combined. How can this problem be addressed if an RDF consumer really wants to use the assertions from all three graphs?
Splitting identities. To avoid such inconsistencies we must first recognize that the resource identity of URI X that was used in the merge of graphs A and B is different -- and disjoint -- from the resource identity of X that we used in the merge of graphs B and C. Thus, to avoid the contradiction that would be created by the merge of graphs A, B and C we can split the identity of X by minting one or more new URIs (or blank nodes) that correspond to these more restricted identities, and use these instead of X in the merge of graphs A, B and C. For example, the merge of A and B might be transformed by the proper substitution of X with a new URI, Xab, throughout; and the merge of B and C might be transformed by the proper substitution of X with another new URI, Xbc, throughout. Finally the transformed merge of A and B can be merged with the transformed merge of B and C to produce a graph that, in effect permits the old X to assume different identities (Xab or Xbc) in different RDF statements. Note also that in such a case, an RDF assertion such as "X p o" from graph B will appear in the final merge as both "Xab p o" and "Xbc p o", because the assertion is being made about both sub-identities of X: Xab and Xbc. For more discussion of splitting identities, see Splitting Identities in Semantic Web Architecture.
Precision versus reusability. There is therefore a trade-off that a URI owner makes in minting a URI and defining its resource identity. A broader URI declaration -- with less constraining core assertions -- permits the URI to be (initially) used in more applications. However, if it is too broad then it may not be precise enough for a particular application. Furthermore, it may cause more down-stream contradictions as the URI is re-used in other graphs and those graphs are later combined, as illustrated before, in Figure 26-inconsistent-graphs.png. On the other hand, a narrower URI declaration -- with more constraining core assertions -- restricts the URI to fewer applications but reduces the likelihood of downstream contradictions. To balance this trade-off, our best advice at present is to choose the degree of precision that will best attract the community of applications that you wish to attract. See also the discussion of “clumping” in URI Declarations in Semantic Web Architecture.
PART 3: Determining Resource Identity
This section proposes a standard process for determining resource identity.How should an RDF consumer, who encounters a URI in a given RDF graph, determine that URI's resource identity? Some of this question is answered by the RDF Semantics specification, but much of it is left to the RDF consumer's imagination and to whatever guidance the RDF consumer derives from the semantic web community. We propose that the following steps, illustrated in Figure 32-identity-algo-sem-ext.png, be adopted as standard. The process described is not new; it has been in use to one degree or another by a number of users for some time. What is new in this paper is merely the documentation of this process and the proposal that this process be recognized as standard.
1. Select assertions – what graph?
In this step, the RDF consumer decides what RDF graph is to be used. If the graph consists of the merge of other graphs, it may be necessary to split the identity of one or more URIs, as described above, in order to avoid contradictions that are discovered when the semantics are applied in step 2.
1.a. Recursively merge ontologies and URI declarations
Once the RDF consumer has decided what starting graph to use, the ontologies and URI declarations referenced by that graph should be merged recursively. For efficiency, ontologies and URI declarations should be cached to avoid unnecessary network requests.
In principle, this merging of ontologies and URI declarations should continue until the transitive closure is reached. (In the case of ontologies, this is known as the ontological closure.) However, this does not mean that every application must actually compute this closure. Indeed, if the RDF graph is large and references many other graphs, the transitive closure could become prohibitively large. An application may, at its discretion, prune this merging process as it sees fit. However, in doing so it runs the risk that it may fail to detect a latent contradiction or it may fail to sufficiently constrain the interpretations for one or more URIs, thus increasing the risk of misinterpreting the RDF graph authors' intent. In pruning this merging process, applications are advised to obtain the URI declarations of predicates and classes, in case they signal semantic extensions.
2. Apply RDF semantics and semantic extensions
This is the only step that is specified in the RDF Semantics specification. It takes as its starting point the merged graph resulting from step 1a, and recursively applies rules from the RDF semantics and any semantic extensions to generate entailments that are merged with this graph until no new entailments result.
This step does not mean that the RDF process is required to apply the entailment rules of every semantic extension that is used by the RDF graph. Rather, it means that if the RDF consumer wishes to obtain all of the entailments that are intended by that graph, then it should apply them.
The need for a semantic extension in this step is signaled by the use of a particular URI as a predicate or as a class (such as an rdfs:Class or an owl:Class), which alerts the RDF processor to implement the entailments for that extension. The extension's entailments may be provided either as a set of rules written in a language that the RDF processor already knows how to process, or as an opaque semantic extension, such as a plug-in to the RDF processor.
At present there is a minor gap in the RDF standards, in that there is no standard way for an RDF processor to recognize that a particular URI is intended to signal an opaque semantic extension: the knowledge of which URIs are intended to signal opaque semantic extensions must be externally supplied to the RDF processor. The RDF processor must magically know about them in advance. It cannot alert the user to the need for a new opaque semantic extension that was previously unknown. This gap could be addressed by defining a standard predicate, such as rdf2:requires, to explicitly indicate when a particular semantic extension is required. However, since it currently seems unlikely that many semantic extensions will be needed that cannot be defined using standard inference rules, this does not seem like a major gap.
As noted in step 1, if a contradiction is discovered that requires splitting the identity of a URI (as described above), then it may be necessary to return to step 1.
The final result of step 2 is to constrain the RDF interpretations that are possible for the resulting graph (including all entailments), as described in the RDF Semantics specification.
3. Select an interpretation
The final step is for the RDF consumer to select an interpretation from the resulting set of possible interpretations. The RDF consumer should be further guided in this selection by rdf:comments associated with the resource, and may be guided by other informal information obtained from the graph or elsewhere.
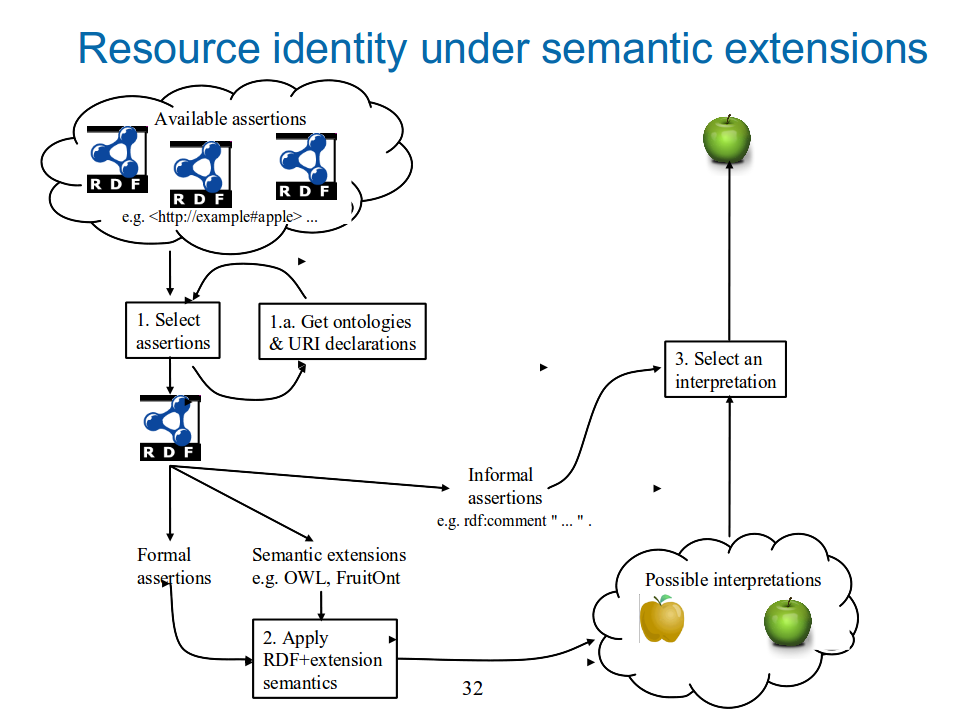
Figure
32-identity-algo-sem-ext.png: Proposed standard steps for
determining resource identity.