Key Points
- What is the value
in knowing that something is an "information resource"?
- Not much unless
it is unambiguously identified
- Unambiguous
identity enables the network effect
- Not merely
naming
- Distinguishing
this resource from all others
- To facilitate
useful machine processing:
- URI consumers
need a deterministic way to determine resource identity
Therefore:
- Need algorithm
for locating authoritative descriptive information -- WebArch
- (Info from URI
owner is considered authoritative)
- A person cannot
be an "information resource"
- Otherwise, no
algorithm for turther determining the identity of the resource
- 2xx response must
imply that the resource is unambiguously identified
And maybe (though I'm not sure)::
- Definition of
"Information resource" must include the URI
- I.e., a
"URI-named network source of representations"
Useful
fiction: A URI names a resource
- Association
between a URI and a resource
- Social
convention
- Allows us to
symbolically manipulate that resource by proxy
What
resource does a URI name?
URI owner can serve
descriptive
information:
- Set of assertions
- Provides a model of that
resource
- Endorsed by URI
owner
Resource Models
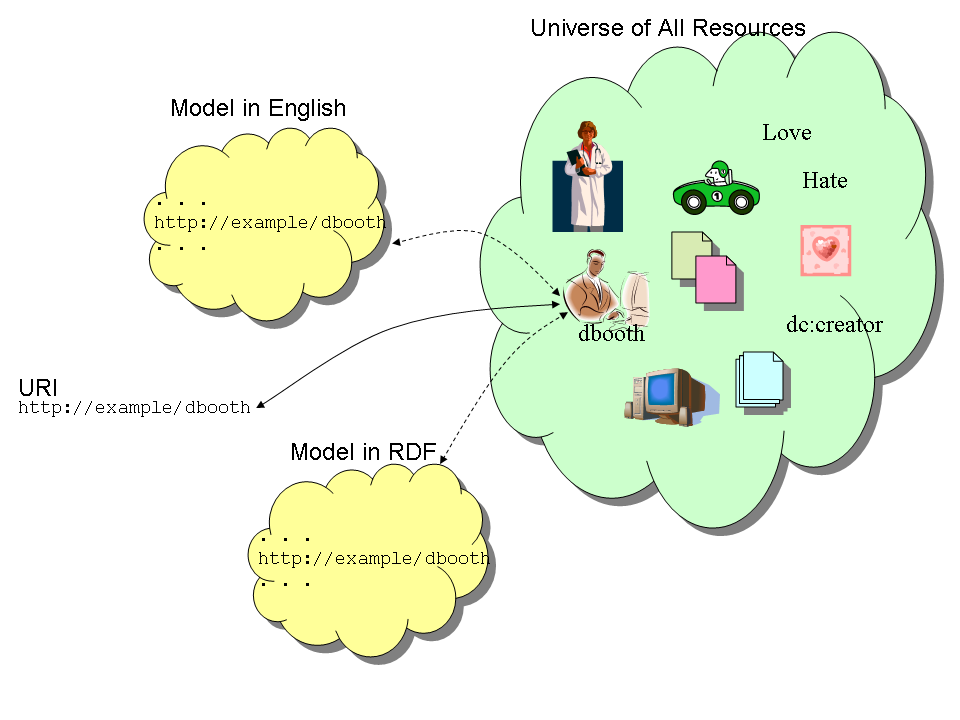
Descriptive
information is inherently partial
- E.g.,
impossible to completely describe a person
-
- One app may
be
content with name, email, physical address
- Another may
need blood type, mass, educational history, etc.
- Most apps
don’t need complete description
The Problem
of resource identity . . .
. . . is the
problem of locating appropriate descriptive information
- Resource
identity doesn’t matter!
. . . or does
it?
Describing
Versus Identifying Versus Naming
Describing:
Providing information about the characteristics of the
resource
Identifying:
Distinguishing the resource from all other resources
Naming: Associating a name with a
resource
Example:
Describing a Resource
___ is:
Example:
Identifying a Resource
___ is:
- an actual, living
person
- with email address dbooth@hp.com
- as of 1-Jan-2005
Warning: Do not confuse
“uniquely identifying” with the “unique name
assumption”.
Unique
Identification Enables the Network Effect
When a resource is uniquely
identified, others can provide independent descriptive
information
- Network effect
- Value of the URI is
increased
Naming
without uniquely identifying
- Identity is
ambiguous
- Users must rely
solely on descriptive information supplied by the URI
owner
-
- (Cannot be
created independently by 3rd parties)
- Value of the
URI is limited
- Network effect
is prevented
Example: “http://hp.example/DavidBooth is the David Booth who
works at HP”
- (Four
“David Booth”s currently work at HP!)
URI
Producers and Consumers
- Producers: URI
Owners
- Consumers:
Users of the URI
Role of URI
Owner (Producer)
- Creates
association between URI and a resource:
- By serving a
2xx code in response to HTTP GET on the URI; or
- By supplying
descriptive information
Role of URI
User (Consumer)
- Discovers
URI
- Looks for
descriptive information
- Tries to figure
out resource identity
URI consumers need a well-defined algorithm for locating
authoritative descriptive information!
Algorithm
for Locating Authoritative Information About a
Resource
Given http URI u:
IF u contains a fragment
identifier, then dereference the racine. (The racine is
all of the URI except the fragment identifier.)
ELSE
Dereference
u.
IF the response code is 2xx, then
conclude that the resource is an “information
resource”.
ELSIF the response code is a 303
redirect to u2, then look for authoritative information at
u2.
ELSE Out of luck.
Should the
same URI name both a person and a Web page?
The WebArch says no.
Why
not? What breaks?
Suppose:
-
u1 names the union of me and my Web page
-
Dereferencing u1 yields a 2xx response
-
u2 names only me
-
u3 names only my Web page
Problem: No algorithm for locating more authoritative information
about u1’s resource!
Distinguishing
between
“information resources” and non-“information
resources”
WebArch is not clear about
how
to tell the difference
Definition needs to
be:
- Clear and unambiguous
- Based on objective
criteria
Class of “information
resources” should be:
- Disjoint from everything else
(except its own subclasses)
My (Latest)
Proposed Definition of “Information
Resource”
An “information
resource” is only a network source of
representations
Is this sufficient to
unambiguously identify the resource if dereferencing the URI yields
a 2xx status? I don’t know. The definition may
need to include the URI, such as:
An “information
resource” is only a URI-named network source of
representations
Key Points
- What is the value
in knowing that something is an "information resource"?
- Not much unless
it is unambiguously identified
- Unambiguous
identity enables the network effect
- Not merely
naming
- Distinguishing
this resource from all others
- To facilitate
useful machine processing:
- URI consumers
need a deterministic way to determine resource identity
Therefore:
- Need algorithm
for locating authoritative descriptive information -- WebArch
- (Info from URI
owner is considered authoritative)
- A person cannot
be an "information resource"
- Otherwise, no
algorithm for turther determining the identity of the resource
- 2xx response must
imply that the resource is unambiguously identified
And maybe
(though I'm not sure)::
- Definition of
"Information resource" must include the URI
- I.e., a
"URI-named network source of representations"
Questions?
Comments?