RDF and SOA
Views
expressed herein are those of the author and do not necessarily
reflect those of HP.
Abstract
The purpose of this paper is not to propose a particular
standardization effort for refining the existing
XML-based, WS* approach to Web services, but to suggest another way of
thinking about Service Oriented Architecture (SOA) in terms of RDF
message exchange, even when custom
XML formats are used for message serialization.
As XML-based Web services proliferate through and between
organizations, the need to integrate data across services, and the
problems of inconsistent vocabularies across services ("babelization"),
will become increasingly acute. In other contexts, RDF has
clearly demonstrated its value in addressing data integration problems
and providing a uniform, Web-friendly way of expressing
machine processable semantics. Might these benefits also be
applicable in an SOA
context? Thus far, the Web services community has shown little
interest in RDF. Web services are firmly wedded to XML, and
RDF/XML serialization is viewed as being overly verbose, hard to parse
and ugly. This paper suggests that the worlds of XML and RDF can
be bridged by
viewing XML message formats as specialized serializations of RDF
(analogous to microformats or micromodels). This would allow an
organization to incrementally make use of RDF in some services or
applications, while others continue to use XML. GRDDL, XSLT and
SPARQL provide some starting points but more work is needed.
Introduction
Although in one sense Web services appear to be a huge success -- and
they are for point-to-point application interaction -- their success is
exposing new problems.
Large organizations have thousands of applications they must
support. Legacy applications are being wrapped and exposed as Web
services, and new applications are being developed as Web services,
using other services as components. These services increasingly
need to interconnect with other services across an organization.
Use cases
For example, consider the following use cases:
- An organization wishes to automate some of its security
administration procedures by connecting and orchestrating several
existing applications, each of which currently uses its own message
formats, domain model and semantics. Applications originally
intended for one purpose need to be interconnected and data needs to be
integrated and reused.
- Each of these applications needs to be versioned independently,
without breaking the orchestrated system.
- After achieving the above, the organization then wishes to
automate the process of periodically auditing the security
authorizations that have been automatically granted by this
orchestrated system. Thus, it must relate the terms and semantics
used by one application at one end of the orchestration to the terms
and semantics used by another application at the other end of the
orchestration.
These use cases are intentionally general. Here are some of the
problems they expose.
XML brittleness and versioning
Perhaps the most obvious problem with XML-based message formats is the
brittleness of XML in the face of versioning. Both parties to an
interaction (client and service)
need to be versionable independently. This problem is a well
recognized, and techniques have been developed to help deal with
it, such as routinely including extensibility points in a schema,
and adopting processing rules such as "Must Ignore" and "Must
Understand" rules. The W3C TAG is currently working on a document
to provide guidance on XML versioning.[XMLVersioning-41]
Even with such
techniques, graceful versioning is still a challenge.
Inconsistent vocabularies across
services: "babelization"
In the current XML-based, WS* approach to Web services, each WSDL
document defines the schemas for the XML messages in and out, i.e., the
vocabulary for that service. In essence, it describes a little
language for interacting with that service. As Web services
proliferate, these languages multiply, leading to what I have been
calling "babelization"[Babelization].
Although some services may use a few common XML subtrees that can be
assumed to have consistent semantics, this is by far the
exception. Typically each service speaks its own language, making
it more difficult to connect services in new ways to form new
applications or solutions, integrate data from multiple services, and
relate the semantics of the data used by one service to the semantics
of the data used by another service.
Schema hell
If we look at the history of model design in XML, it can be
characterized roughly
like this. At first, XML schemas were designed in isolation
without
much thought to the future:
- Version 1: "This is the model."
Pretty soon the designers realized that they
forgot something in the first version, so they produced a new schema:
- Version 2: "Oops! No, this is
the model."
After making the same mistake once or twice, designers realized that
they needed to plan for the future, so they got a little smarter and
started adding extensibility into the schema:
- Version 3: "This is the model today,
but here is an extensibility point
for tomorrow."
This was fine for minor improvements, but before long the application
was merged with another application that already had its own schema, so
the designers had to make a new, larger schema that combined the two:
- Version 4: "This is the super model (with extensibility
for tomorrow, of course)."
This again was fine for a little while, until the application needed to
interact with two other applications that had their own models.
And since these other applications were owned by different vendors,
there was no way to force them to use the first model. So, to
facilitate smooth interaction across these applications, yet another,
larger model was developed:
- Version 5: "This is the
super-duper-ultra model (with
extensibility, of course)."
Sound familiar?
What's wrong with the model?
There are two basic problems with this progression. The first of
course is the versioning challenge it poses to clients and services
that use the model. The second is that over time the model gets
very complex. It typically resorts to using a lot of
optionality in order to be all things to all applications and allow for
extensibility. Thus, where
initially the schema was intended as a concise description of what the
service expects, in the end it becomes a maintenance nightmare,
obscuring the true
intent of the service. Furthermore, each application or component
within an application often only needs or cares about one small part of
the model.
Like a search for the holy grail, this eternal quest to define the model is forever doomed to
fail. There is no such thing as
the model! There
are many models, and there
always will be. Different applications -- or even different
components within an application -- need different models (or at least
different model subsets). Even the same service will need
different models at different times, as the service evolves.
Why do we keep following this doomed path? The reason, I believe,
is deeply rooted in the XML-based approach to Web services: each
service is supposed to specify the
model that its client should use to interact with that service,
and XML models are expressed in terms of their syntax, as XML
schemas. Thus, although in one sense the XML-based approach to
Web services has
brought us a long way forward from previous application integration
techniques, and has reduced
platform and language-dependent coupling between applications, in
another sense it is inhibiting even greater service and data
integration, and inhibiting even looser coupling between services.
Benefits of RDF
RDF[RDF] has some
notable characteristics that could help address these problems.
Easier
data integration.
RDF excels at data integration: joining data from multiple data models.
- In RDF, models are merged simply by merging sets of
assertions. Models that already use the same terms (URIs) will
automatically join on those URIs. In XML, models are merged by
crafting a new XML model that includes the previous models.
Because XML is (mostly) tree-based, trying to express common subtrees
(by reference) is awkward.
- In RDF, relationships between models can be explicitly modeled in
RDF. Thus, a merged model can capture not only the constituent
models, but the relationships between those models. In XML there
is no standard way to express relationships between portions of the
constituent XML models.
- In RDF, the merged model and its constituent models can all
coexist and be accessed simultaneously as subgraphs of the merged
model. In XML, the original constituent models usually are not
direct subtrees of the merged model.
Easier
versioning. RDF
makes it easier to independently version clients and services.
- RDF is syntax-independent, so there is less of a syntactic
compatibility issue when something new must added to a model.
- RDF uses the Open World Assumption (OWA), which permits
additional data to be added to a model without affecting existing uses
of that model.
- Simple inferencing is easy in the RDF world. This means,
for example, that if a model is versioned to either combine two facts
that were previously represented as one, or vice versa, the core
service can be insulated from the impact of this change. The core
service merely needs to ask for the fact (for example, as a SPARQL
query), and the reasoner can deduce it if it did not already exist
directly.
This is not to say that all
versioning issues disappear with the adoption of RDF, since RDF
ontologies still need to be versioned. But it is easier for old
and new models to coexist in RDF than in XML.
Consistent
semantics across services.
There are a few reasons for this.
- RDF is grounded in URI space. This allows URIs to act as a
universal, common vocabulary. In contrast, XML uses QNames.
- RDF is not context dependent. In contrast, the meaning of
an XML fragment is dependent on its context.
- RDF data models are independent of syntax. In contrast, XML
models are defined in terms of their syntax. Thus, two XML
fragments that are syntactically different, but are intended to carry
the same semantics, are not automatically recognizable as being
semantically equivalent.
Emphasis
on domain modeling.
- RDF encourages you to talk about the problem domain -- classes
and relationships between them -- while XML is focused on modeling the
document. Of course, good designers in XML will try to model the
domain, but XML provides less encouragement to do so.*
Weighing the benefits
XML experts may claim that an RDF approach would merely be trading XML
schema hell
for RDF ontology hell, which of course is true, because
as always there is no silver bullet. Any technology has its
difficulties, and RDF ontologies are no exception. But RDF
ontology hell seems
to scale and evolve better than XML schema
hell, again because it provides a uniform semantic base grounded in
URIs, old and new models peacefully coexist, and it is syntax
independent. This allows ontologies that
are
developed and evolved independently to be merged more easily than with
XML schemas.
Furthermore, these benefits will become increasingly important over
time, as Web services become
ubiquitous, business demands accelerate ever more rapidly, and services
and data need to be integrated on ever larger scales more quickly and
easily.
Complexity issues will become increasingly dominant; processing
overhead will become less important.
An RDF approach may at first appear to be more complex than an XML
approach, because developers must come to grips with new terminology
(based on lofty mathematical foundations) and a new way of processing
and thinking about their data. Indeed, the RDF approach is more complex at the micro level
of a single service that never evolves. But at the macro level,
as the problem scales, the universal simplicity of RDF triples grounded
in URI space shines through.
Data validation
Although thes above benefits of RDF are fairly clear, one current
strength of XML is document validation. It is helpful to be able
to validate instance data against the XML schemas that a service
provides.
RDF and XML differ dramatically in their treatment of data
validation. RDF normally uses the open world assumption (OWA),
whereas XML is closed world (normally). Extra data in XML
is normally an error, whereas in RDF it is ignored. Missing data
in XML is normally an error; in RDF it may be inferred, which, if not
prevented, can lead to unexpected results in some cases. This is
generally true (due to the OWA) even if RDF-S and OWL are used to
express constraints on the desired model.
At first glance, it may seem that the OWA would inherently inhibit the
ability to do effective data validation in RDF beyond consistency
checking and generic heuristic checks. In fact, the situation is
just different. There are ways that the world can be temporarily
closed in RDF, in order to check for missing (unbound) data.
SPARQL, in fact, may prove to be a very convenient tool for validity
checking of RDF application data: a
sample query can be provided, such that if the query succeeds, the data
is known to be complete.
What kind of data validation is needed in an SOA? Services
and clients act as both data producers and data consumers. We can
therefore distinguish two kinds of validation that would typically be
desired of instance data.
- Model integrity (defined
by the producer). This is to ensure that the instance makes
sense: that it conforms to the producer's intent, which in part may be
constrained by contractual obligations to consumers.
Since a data
producer is responsible for generating the data it sends, it should
supply a way to check model integrity. This validator may be
useful to both producers and consumers. However, because the
model may change over time (as it is versioned), the consumer must be
sure to use the correct model integrity validator for the instance data
at hand -- not a validator intended for some other version -- which
means that the
instance data should indicate the model-integrity validator under which
it was created.
- Suitability for use
(defined by the consumer).
This depends on the consuming application, so it will differ between
producer and
consumer and between different consumers. Since only the data
consumer really knows how it will
use the data it receives, it should supply a way to check suitability
for use. This may also include integrity checks that are
essential
to this consumer, but to avoid unnecessary coupling it should avoid any
other checks.
Thus a message sent from producer to consumer may be validated by: (a)
the model-integrity validator that the producer supplies; and (b) the
suitability-for-use validator that the consumer supplies. As the
producer and consumer are versioned independently, these validators may
also be versioned and the appropriate version of each mush be
applied. The appropriate versions are easy to determine, of
course: the message itself should indicate the appropriate
model-integrity validator, and the suitability-for-use validator
depends on the specific consumer receiving the message.
SPARQL may be useful for both of these cases: instead of supplying an
XML schema, a data producer or consumer could supply a sample SPARQL
query for data validation. If the query succeeds, then the data
passes the validation test.
RDF: the lingua franca for data exchange
For the reasons described above, I expect RDF to eventually become the
lingua franca for data exchange, even if XML and other syntaxes are
used for serialization. (See my PowerPoint or PDF slides from the Semantic Technology
Conference 2008 for more explanation of why and how.) After
all, who really cares about
syntax? Sure, an application receiving a message needs to be able
to parse the message, but parsing isn't the point. What matters
is the semantics of the
message.
REST, SPARQL endpoints and pull
processing
Thus far we've implicitly assumed that messages will be sent from producer to consumer,
but this is a bad assumption. The REST
style of interaction is more flexible than the WS* style of Web
services, and more typically involves pull
processing: the consumer asks
for the data it needs. This helps reduce coupling between
consumer and producer because the producer doesn't have to guess what
the consumer needs. To do this, a producer can simply
expose a REST style SPARQL endpoint and let the consumer query for
exactly what it needs, thus reducing the data volume that needs to be
transmitted and permitting the producer to be versioned more
freely.
Of course, for some producers a SPARQL endpoint will be too
heavyweight. Furthermore, even when using REST, sometimes it is
necessary to actively send information,
such as with POST.
For these cases, there are still benefits in sending RDF. But as
the next section explains, that RDF does not necessarily need to look like RDF.
RDF in an XML world: Bridging RDF and XML
It's all fine and dandy to tout the merits of RDF, but Web services use
XML! XML is well entrenched and loved. How can these two
worlds be bridged? How can we incrementally gain the benefits of
RDF while still accommodating XML?
Treating XML as a specialized
serialization of RDF
Recall that RDF is syntax independent: it specifies the data model, not
the syntax. It can be serialized in existing standard formats,
such as RDF/XML or N3, but it could also be serialized using
application-specific formats. For example, a new XML or other
format can be defined for a particular application domain that would be
treated as a specialized serialization
of RDF in RDF-aware services, while being processed as plain XML in
other applications. A mapping can be defined (using XSLT or
something else) to transform the XML to RDF. The Semantic
Annotations for WSDL and XML Schema [SAWSDL] work might be quite
helpful in defining such mappings. Gloze [Gloze]
may also be helpful in "lifting" the XML into RDF space based on the
XML schema, though additional domain-specific conversion is likely to
be needed after this initial lift. GRDDL [GRDDL] provides a
standard mechanism for selecting an appropriate
transformation.
In fact, this approach need not be limited to new XML or other formats:
any existing format could also be viewed as
a specialized serialization of RDF if a suitable transformation is
available to
map it to RDF. This approach is analogous to the use of
microformats or micromodels, except that it is not restricted to
HTML/xhtml, and it would typically use application-specific ontologies
instead of standards-based ontologies.
Dynamic input formats
Transformations provided for normalizing input to RDF do
not necessarily need to be a static set, known in advance. They
could also be
determined dynamically from the received document or its referenced
schema. For example, suppose the normalizer receives an input
document that is serialized in a previously unknown XML format.
If the document contains a root XML namespace URI or a piece of GRDDL
that eventually indicates where an appropriate transformation can be
obtained, then the normalizer could automatically download (and cache)
the transformation and apply it. Standard, platform-independent
transformation languages would facilitate this. (XSLT?
Perl? Others?) Of course, security should be considered if
the normalizer is permitted to execute arbitrary new transformations,
either by sandboxing, permitting only trusted authorities to provide
signed transformations, or other means.
Generating XML views of RDF
On output, a service using RDF internally may need to produce custom
XML or other formats for communication with other XML-based
services. Although we do not currently have very convenient ways
to do this, SPARQL may be a good starting point. TreeHugger[TreeHugger]
and RDF Twig[RDFTwig]
could also be helpful starting points.
Again, these output transformations do not necessarily need to be
static. For example, in a typical request-response interaction, a
client making a request (or perhaps a proxy along the way) might
specify the desired response transformation along with the request.
Finally, the input normalization and output serialization need not be a
part of
the service itself. For example, these functions might be
performed by a proxy or a
suitable broker or Enterprise Service Bus (ESB).
Defining interface contracts in
terms of RDF messages
Although the RDF-enabled service may need to accept and send messages
in custom XML or other serializations, to gain the versioning benefits
of RDF it is important to note that the interface contract should be
expressed, first and foremost, in terms of the underlying RDF
messages that need to be exchanged -- not the serialization.
Specific clients that are not RDF-enabled may require particular
serializations that the service must support, but this should be
secondary to (or layered on top of) the RDF-centric interface contract,
such that the primary interface contract is unchanged even if
serializations change.
An RDF-enabled service in an XML world
The diagram below illustrates how an RDF-enabled service might work.
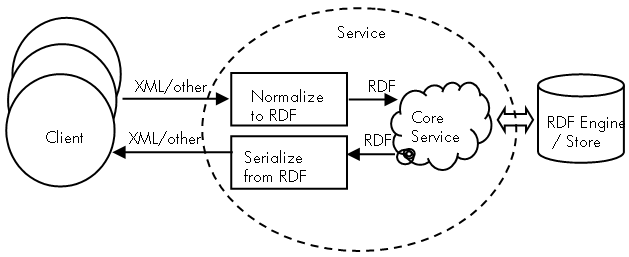
- Different clients might require different serializations.
- Input is normalized from its serialization to RDF prior to use by
the core service. This insulates the core service from details or
changes in the serializations.
- Once the data is in RDF, the core service can access it from an
RDF data store, thus facilitating the use of simple inferencing that
can either insulate the core service from model changes, or be
leveraged for application specific purposes.
- Output is generated in whatever serialization is required, as an
application-specific view of some RDF data.
- Input normalization and output serialization could instead be
done in a proxy or ESB outside of the service.
XML transformations and versioning benefits
One may wonder what benefit is gained with this approach if the service
still needs to support clients with custom XML formats anyway. It
is true that for those clients, no versioning benefit is gained (though
consistent semantics may still be gained), because the client is
already locked in to its particular message formats and there is
nothing that can be done about it. However, the point is that the
core
service is not locked in to
that message format, so the service can still benefit in two ways: (1)
it can
simultaneously support multiple message formats (such as different
versions) while still using the same RDF models internally; and (2) it
can still evolve its internal RDF models and support other clients
that can accept more sophisticated models, without breaking clients
that are locked into an older message format. And of course, if a
client can speak RDF directly, even greater versioning flexibility and
decoupling is obtained.
Note that these versioning benefits are only relevant to the individual
messages that are exchanged, and that is only a part of the total
versioning picture, which may also involve versioning the choreographed
process flow between the client and service. Changes to the
client/service process flow can be much more disruptive than changes to
individual message formats. RDF does not address that
problem. That is the problem that REST
addresses, and it is
largely orthogonal to the subject of this paper. (RDF addresses
the need for graceful evolution of client/service message models,
whereas REST addresses the need for graceful evolution of
client/service process flows.)
Granularity
Transformations from XML to RDF can be done with any level of
granularity:
- Fine grained: Every
element, attribute, etc., in XML maps to one or more RDF
assertions. This permits more detailed inferences, but adds more
complexity and processing up front.
- Coarse grained: An entire
chunk of XML maps into some RDF assertions. Or, the XML chunk may
be retained in the RDF, and the transformation may generate RDF
metadata that annotates it. This is simpler and involves less
processing up front, but information inside the chunk is less
accessible to the application. It also means carrying these XML
chunks around.
It seems likely that different applications may merit different levels
of granularity. I don't yet know what guidance to give on
this. It would be helpful to develop some best practices.
RDF and efficiency
I have heard statements to the effect that "My friend Joe tried RDF
once and said it was really inefficient." There is some overhead
in using RDF, but RDF is not inherently very inefficient. If your
application needs to do the kind of processing that RDF facilitates,
then it must be done somewhere, and tools like Jena, Arq, etc., are
actually pretty good at the job they do. In fact, they are
probably more efficient than what most programmers could implement if
they tried to do these things themselves using custom
logic.
On the other hand, there is a
learning curve for RDF. Just as in learning any programming
language or learning how to write relational database queries in SQL,
the programmer must learn what kinds of things can be done efficiently
in RDF and what should be avoided.
Finally, this efficiency objection becomes increasingly meaningless
over time, as processing costs decrease and the need to more rapidly
evolve and integrate dominates.
Summary of Principles for RDF in SOA
The following seem to be key principles for leveraging RDF-enabled
services in an SOA.
- Define interface contracts as though message content is RDF
- Permit custom XML/other serializations as needed
- Provide machine-processable mappings to RDF
- Treat the RDF version as authoritative
- Each data producer supplies a validator for data it creates
- Each data consumer supplies a validator for data it expects
- Choose RDF granularity that makes sense
Conclusion and suggestions
Although we have some experience
that suggests this approach is useful, there are still some
technology gaps, and we need practical experience with it. To
this end, here is what I would like to see:
- More exploration of paths for the graceful adoption of RDF in an
XML world. Techniques to facilitate the coexistence of XML and
RDF in the context of SOA.
- More work on techniques for transforming XML to RDF. GRDDL
is a good step, and XSLT is one potential transformation
language. Are there better ways?
- More work on ways to transform RDF to XML. SPARQL seems
like a good start.
- More work on practical techniques for validating RDF models in an
SOA context. SPARQL may be one good approach. Are there
others?
- Best practices for all of the above.
Acknowledgements
*Thanks to Stuart Williams for helpful comments and suggestions on this
document.
19-May-2009: Updated my
email address.
12-Jun-2008: Corrected
typo and added links to my Semantic Technology Conference 2008 slides.
31-Mar-2008: Added mention
of RDF as lingua franca, and the role of SPARQL endpoints.
06-Jun-2007: Added named
anchors to section titles.
02-Apr-2007: Renamed
"basic data integrity" to "model integrity" and mproved
explanation of document validation.
25-Feb-2007: Clarified
versioning benefits; added mention of REST for process versioning.
29-Jan-2007: Added mention
of W3C work on Semantic Annoatations for WSDL and XML Schema.
24-Jan-2007: Added
explanation of dynamic normalization and mention of ESBs.
16-Jan-2007: Tweaked the abstract for greater clarity.
11-Jan-2007: Original version.