URI Declaration Versus Use
Views
expressed herein are those of the author and do not necessarily
reflect those of HP.
Abstract
A URI declaration
permits assertions about a URI's associated resource to be classified
into two groups: core assertions,
whch are provided by the URI declaration, and ancillary assertions, which are all
others. This distinction
enables different parties to share a common understanding of the
associated resource (by accepting the core assertions) while making
different choices about which ancillary
assertions to accept. This paper defines these concepts and proposes
some related best
practices and a Web
architectural
rule specifying how URIs for non-information resources can be
conveniently declared using existing hash or hashless (303-redirect)
URI
mechanisms.
Table of Contents
Introduction
The Semantic Web's use of a URI as a globally scoped name conveniently
enables anyone to make assertions about the denoted resource.
Many such assertions may be made by many parties -- both the URI owner
(minter) and other users of the URI. The URI user thus faces the
question of which of potentially many assertions to use. Some of
these assertions may be mutually incompatible -- contradictory -- and
some may be incompatible with the user's intended application or
beliefs. Clearly the question of which assertions to use will
depend both on the user's application, as different sets of assertions
may be best suited to different applications, and on the user's
good judgement in selecting those that he/she believes
are the most trustworthy and suitable. But is there a common
subset of assertions that all users
of the URI should use when they use the URI to make statements about
its denoted resource? Yes.
This paper argues that it is important to Semantic Web architecture to
distinguish between core assertions
for a URI, which are mandatory for anyone choosing to use that URI to
make statements about the resource it denotes, and ancillary
assertions for the URI, which are optional. Core
assertions are those provided in an authoritative declaration for that URI; all
other assertions involving that URI are ancillary assertions.
A URI declaration therefore represents what
Pat Hayes calls a "baptism"
of the URI: loosely, its purpose is to establish the association
between the URI
and whatever resource that URI is intended to denote. It does
this
by "baptising" a set of assertions -- the core assertions
-- that characterize the intended resource. However,
since it is not possible in a theoretical sense to ensure that these
core assertions will actually be interpreted as identifying the
intended resource, more precisely a URI declaration only specifies the
first step in a two-step
mapping::
Step 1: A
mapping from the URI to a set of core assertions that are intended to
characterize the resource; then
Step 2: An interpretation of those core assertions as identifying the
actual resource.
Step 2 is outside the control of Semantic Web architecture. It is
inherently ambiguous and is left for philosophers to ponder.
Fortunately, step 1 is what matters to to Semantic Web applications,
and this is what URI declarations address.
The ideas behind URI declarations are not new. A number of people
in the Semantic Web community have used and
advocated practices
that implicitly amount to URI declaration. For example, Dan
Connolly's paper on "A
Pragmatic Theory of
Reference for the Web" recommends:
1. To
mint a
term in the community, choose a URI of the form doc#id and publish at
doc some information that motivates others to use the term in a manner
that is consistent with your intended meaning(s).
2. Use of a URI of the form. doc#id implies agreement to
information published at doc.
Thus, this paper is an attempt to
crystalize and standardize concepts, terminology and practices that had
previously been vague, unnamed and not universally
accepted in the Semantic Web community. The
ideas presented here are thus relevant to the Semantic Web community in
three ways:
- They help clarify architectural issues and discussions around
best practices.
- For URI owners (minters), they offer guidance about how a URI
declaration should be provided, and what it should contain.
- For URI users (both readers and writers), they offer guidance
about how a URI should be used
and what additional assertions should be made using the URI.
For convenience, this paper focuses on URIs that denote something other
than Web pages or Web sites, i.e., non-information
resources, but the principles discussed here are also applicable
to information resources. Also, although this paper is
written in terms of URIs,
the concepts apply equally to IRIs. (See RFC 3986 and RFC 3987 for advice on
minting URIs and IRIs.)
Example: A URI for the Moon
Suppose I mint a URI to denote the moon: http://dbooth.org/2007/moon/
. I own the domain dbooth.org, so according to the AWWW's guidance
on URI ownership, I have the authority to do
so. Since the moon is not an information resource, in
conformance with the W3C
TAG's httpRange-14 decision I have
configured my server such that an attempt to dereference that URI will
result in a 303-redirect to http://dbooth.org/2007/moon/decl.html
, which, when dereferenced, returns a page containing the following
statements:
Although the above assertions were expressed informally in
English prose, they might instead have been expressed formally in a
machine-processable langauge such as RDF and look something
like the
following N3
excerpt (omitting the usual rdfs: prefix
declaration and the
irrelevant foo: prefix declaration):
For the purposes of this paper, it does not matter whether the
assertions are expressed formally or informally, though to be most
useful in
the Semantic Web they should be expressed either directly in RDF or
indirectly in an XML format that has a GRDDL transformation to RDF.
URI declaration
Definition: A URI declaration is a set of statements, or "core
assertions", that
authoritatively declare
the association between a URI and a particular resource.
A URI declaration involves a performative speech act. (See Cowen's
message or Wikipedia.)
Its publication by someone who has the authority to make the
declaration -- the URI owner or delegate -- creates the
association between a URI and a resource. Therefore, any
party wishing to use that URI to make statements about its denoted
resource should take all
assertions that constitute part of that URI declaration -- the core assertions -- as true by
definition. In the moon example above, the core assertions are
M1a, M1b and M1.c.
Proposed
rule R0: Any party using
a
URI to make statements about the URI's denoted resource should use that
URI in a manner consistent
with the URI's declaration.
This is a take-it-or-leave-it proposition: If you do
not want to accept the core assertions specified by the URI
declaration, then you
should not use that URI to make statements about its denoted resource,
because in essence you
may be trying to talk
about a different resource -- one that shares some, but not all, of the
same characteristics. Of course, violations of this rule
may be completely invisible when committed by an application in the
privacy of
its own RAM, so in practise this rule is most relevant when statements
(ancillary
assertions) are written or published about the resource.
Suggested
practice P1: A URI declaration
should include sufficient information to
distinguish the denoted resource from other resources. [Is there a
WebArch reference for this? The closest I
find is
Good practice:
Identify with URIs.. -- DBooth]
For example, statement M1.a above ("http://dbooth.org/2007/moon/
is a moon") is not sufficient to uniquely identify the intended
resource, because there are many moons in the universe. However
M1.a and M1.b
together are sufficient, at least for many purposes. By
definition M1.c is also a core assertion, but in this case its
effect is merely informative: it has no impact on the identity
of the
denoted resource because it is trivially satisfiable regardless of what
resource the URI denotes.
Beware that
sufficient information to uniquely identify the resource for one
purpose may not be
sufficient information for another purpose. Pat Hayes has several
times pointed out that one application may require finer (or different)
distinctions than another. (See Hayes' message
on the URI/identity issue or his IRW presentation "In
Defense of Ambiguity".) Thus, P1 is a guideline -- not a hard
and fast rule.
@@ Add link to paper on
disambiguating @@
Furthermore, although the intent of a URI
declaration is to supply core
assertions that uniquely identify the denoted resource, there is no
requirement that the core assertions be limited to assertions about
that resource. For example, if the URI declaration for http://dbooth.org/2007/moon/
had contained an additional core assertion stating "Elvis is king",
users would have been required to accept this assertion or forego use
of the URI. This may seem odd, but there are two reasons for
it. One is that some statements that are not directly about the
moon may still represent assumptions that are important to the proper
understanding and use of the URI. The other is that I do not know
of any practical and objective way to judge whether an assertion is
relevant or not, because its relevance may depend on the minter's
intent. I would be interested in ideas for other approaches that
would limit the assertions to those that are relevant to the denoted
resource.
Definition: A URI declaration page is an information resource whose primary
purpose
is to provide URI declarations.
A URI declaration page is quite similar to the idea of a Published
Subject Indicator. However, a single URI declaration
page could contain declarations for multiple URIs. Thus, the
relationship between URI declaration pages and resources is
many-to-many.
Names versus resources
We are treating a URI as a name for a resource, so that when the name
is used in an assertion about the resource, it will be understood as
referring to, or denoting, the resource. But the treatment
of a name in
an explicit name declaration is very different: it is treated simply as
a literal sequence of characters. Thus, in the URI declaration
phrase 'The URI "http://dbooth.org/2007/moon/"
hereby names . . .', http://dbooth.org/2007/moon/
refers only to a sequence of characters that conforms to URI syntax,
whereas in the statement "http://dbooth.org/2007/moon/
is a moon" it refers to a resource. In other words, the subject
of a URI declaration as a whole (i.e.,
M1 as a whole) is a URI string -- not the denoted resource --
whereas the subject of a
normal assertion is the denoted resource, even though the subordinate
parts of
the URI declaration that constitute the core assertions (M1.a, M1.b and
M1.c) use resources as
subjects.
This distinction between a name as a simple string versus the thing it
denotes is critical to the idea of a URI declaration. It is
readily apparent in languages like Java or C++
that use explicit name declarations, and the distinction has been made
evident in the example above by using such stilted phrasing as 'The URI
"http://dbooth.org/2007/moon/"
hereby names . . .'. But there is no such distinction in
bare RDF, because RDF does not have (or need) name
declarations. (Named
graphs, however, extend RDF to make this distinction and
enable a URI as a string to be associated with a graph.) This is
why there is no visible difference between
core assertions and ancillary assertions when they are expressed in
RDF. The difference is created by their context: core assertions
are those specified by the URI declaration, and all others are
ancillary assertions.
Components of a URI declaration
More precisely, a URI declaration consists of:
- a URI u;
- a predicate p(x), where
x is a resource; and
- a performative speech act, issued by the URI's owner or delegate,
that indicates u and p(x).
The URI declaration can be understood as stating:
"If a resource r exists such that p(r) is true, then henceforth u denotes r."
If the predicate p is
expressed as an RDF graph, then a URI declaration is analogous to
a named
graph, where p is the
graph and u is its
name. However, instead of u
denoting p itself, u
denotes the resource that satisfies p.
It is important to realize that the mere pairing of u and p does not constitute a URI
declaration without a distinguishable speech act or evidence
thereof. Thus, a
critical aspect of any mechanism for making URI declarations is the
ability to distinguish the performative speech act from other, normal
speech. There are many ways this can be done; usually context is
involved. Also, in some sense the evidence that such a speech act
has occurred is more important than the act itself, because what
matters is that other parties believe
that such an act has actually occurred. Thus, a digitally
signed statement provides evidence that the signer made the signed
statement, even if the reader did not witness the act of making or
signing the
statement.
In the moon example above, the performative speech act is the act
of publishing statement M1 ("The URI 'http://dbooth.org/2007/moon/'
hereby names . . . ."), URI u
is http://dbooth.org/2007/moon/
, predicate p(x) is the
conjunction of M1.a, M1.b and M1.c, and x
is the moon. Note that if we had added a statement M2 saying "http://dbooth.org/2007/moon/
is made of green cheese" to the URI declaration then (at least in
many models of the universe) there would be no way to satisfy p(x), because there is no moon that
orbits the Earth and
is made of green cheese.
URI declaration and resource identity
The notion of URI declaration also helps shed light on the question of
resource identity. By design, a URI denotes one
resource. But what resource
does it denote? This question has plagued Web architecture
discussions for some time. (See WWW2006 workshop on
Identity, Reference and the Web.) But if we view this
question operationally as asking "What assertions
should be used if the URI is used?" then the answer becomes simply:
"The
core assertions provided by the URI declaration".
What does "authoritative" mean?
The word "authoritative" has sometimes caused confusion in discussions
of URI declarations. If a URI 303-redirects to a URI declaration
page, or if it has a fragment identifier and the racine
(the part before the hash "#") that leads to a URI declaration
page, in what sense
is a URI declaration made by that page "authoritative"? Does it
mean that:
- the assertions in the URI declaration are necessarily true?
No.
- the author of that page believes
that the assertions are true? Not necessarily.
- the author of that page is a recognized expert on the subject of
that page? No.
- the URI owner gets to control what others may say about the URI's
associated resource? No.
- the URI is the most popular or dominant URI for denoting the
associated resource? No.
- [Are there other examples I
should have included here?]
A URI declaration is authoritative only in defining the association between the declared
URI and a particular resource. (More precisely, it defines the
first part of this
association, as explained above.) The
declaration creates a social
expectation that other parties making use of that URI will use it to
denote that same resource. (More precisely, it creates the social
expectation that a party using the URI to denote its resource agrees
with the core assertions in the URI declaration.) This is
analogous to the social
expectation that is created when a standards organization publishes a
specification named XYZ and
a product manufacturer then advertises an XYZ product. If that product
does not conform to the XYZ specification,
the manufacturer will be viewed as having violated a social
expectation.
Ancillary assertions
A URI declaration gives special importance to the assertions that are
part of that declaration in order to distinguish them from other
assertions about the associated resource. Ancillary assertions are any
statements about the URI's associated resource that are not a part of
the URI declaration. They may be made by the URI owner or anyone
else. In contrast with assertions that comprise the URI
declaration, ancillary assertions are optional when using a URI,
regardless of who issues them: a URI user may choose to assert or not
assert (i.e., to believe or not believe) ancillary assertions while
using the URI.
For example, http://dbooth.org/2007/moon/about.html
contains two
ancillary assertions, M11 and M12:
A user electing to use http://dbooth.org/2007/moon/
to denote the moon must accept assertions M1.a, M1.b and M1.c, but may
or may
not assert M11 and M12.
Why distinguish between URI declarations and
other assertions?
Why do URI declarations matter? Why is it architecturally
important to distinguish between core assertions and ancillary
assertions? The answer is "to facilitate data reuse", but to
explain why it facilitates data reuse, we should state a couple of
assumptions.
Assumption 1: When minting a URI for a
resource, the URI minter publishes a description of that resource.
This does not always happen, but it clearly is recommended
best practice to do so. So for the purpose of this
explanation we will assume that it does happen, and we will view the
resource
description conceptually as a set of assertions, whether they are
expressed formally or not. At one extreme, it may be an empty
set, but we will ignore that case since it is equivalent to not
publishing a resource description at all. At the other extreme,
the minter's resource description may include all assertions that the
minter has reason to believe about the resource.
Assumption 2: URI users will need
additional assertions about the resource, beyond what the URI
minter supplied. For example, the user may be combining
assertions from several sources. This act of combining assertions
from multiple sources is what the Semantic Web is all about, so this
seems like a reasonable assumption.
A URI declaration anchors the URI's meaning
Given these assumptions, the establishment of a set of mandatory core
assertions permits the meaning of a URI to be anchored, to prevent it
from drifting, and this in turn increases the
likelihood that independent assertions made using the URI can be
successfully joined. Here's how.
Different applications have different needs. Thus, different URI
users will necessarily wish to make different sets of assertions
involving the
URI. Some of these sets of assertions will be mutually
incompatible, in spite of the fact that each set may be useful and
valuable for some applications. One reason why this happens and
needs to be permitted to happen is that when the real world is modeled
formally, approximations are made. An approximation
that is good enough for one application may be inadequate for another
application (and may lead to logical inconsistency). For example,
it is not
possible to completely characterize a real world entity such as a
person. This does not mean that precision and
correctness should be abandoned. Rather, the point is to
acknowledge that precision
and correctness must be evaluated in relation to a
particular application: they are not universal.
On the other hand, a key point in the use of URIs in the Semantic Web
is to enable independently created data to be readily integrated, and
useful
new conclusions to be reached, by joining assertions that use the same
URI. How can the desire for integration be reconciled with the
fact that some
sets of assertions will not be usable together? First,
observe that different users will need to make their own choices about
which sets of assertions to use. There will be no universal
answer to the question: "Which sets of assertions should I use?"
The right answer will vary depending on the application and
context. If there is no commonly agreed-upon URI
declaration -- if all
sets of assertions made with the URI were equally optional -- then
there would still be some possibility of being
able to use two sets of assertions together. But if
there is a set of core assertions that all users must accept, then the
likelihood of compatibility can be increased by increased clumping, as
explained below.
Clumping assertions facilitates reuse
Clumping is the effect of assertion sets being drawn closer together,
to have more assertions in common, in a manner similar to the network effect.
Clumping is caused by a combination of naming and "gravity".
Naming
By giving a name to a
particular set of assertions, and publicizing that name, a URI
declaration makes it easier to use the assertions repeatedly:
- the potential user already knows that the items in the named
chunk are
compatible with each other, so the effort required to evaluate them is
reduced; and
- once the user has gotten to know a particular named set, it can
be
reused repeatedly as a standard, instead of separately evaluating the
details of many different bundles that vary slightly from each other.
The benefits of naming are profoundly evident in software and
copyright licensing: it is far easier to evaluate and get to know a few
standard software or copyright licenses such as the Creative Commons GNU
GPL, LGPL,
BSD and Attribution
licenses than to separately evaluate a custom license for every work
that one considers using.
Gravity
The effect of naming would help facilitate reuse even if the core
assertions were
not mandatory. But having them mandatory helps in a second,
closely related way.
Suppose the core assertions A1 for a URI were optional
(like ancillary assertions), and two Semantic Web applications AppB and
AppC were
independently developed to use two sets of assertions, B and
C involving that URI, as shown in Figure 1 below.
Core assertions A1 may be close enough
to some of what AppB and AppC need that AppB and AppC may be written to
take advantage of them. Indeed, by virtue of being provided in
the URI declaration, core assertions A1
are more likely to be used than third-party ancillary assertions, so
the naming effect already pulls B and C closer together even
if core assertions A1 are considered optional.
But if core assertions A1 are optional, then AppB and AppC may choose
to use different subsets of A1. Any assertions that are in common
between B and C (the intersection) are known to be compatible, but the
assertions in A1 that are not in
common could conflict with other assertions in either B or C. For
B and C to be used together by a
third application, they must not conflict, so if the likelihood of
conflict can be further reduced then reuse will be
better facilitated.
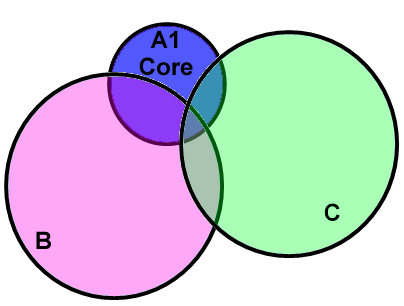
Figure 1: AppB and AppC are developed
independently to use assertion sets B and
C, respectively. If core assertions A1 are optional, then B and C
may partially overlap them.
For any application, there is a range of ways that the
application can be implemented. Thus, if core assertions A1 are
mandatory instead of optional, then AppB and AppC may be written
slightly differently to accommodate and potentially take advantage of
them, thus using sets B' and C' of assertions instead
of B and C, as shown in Figure 2 below.
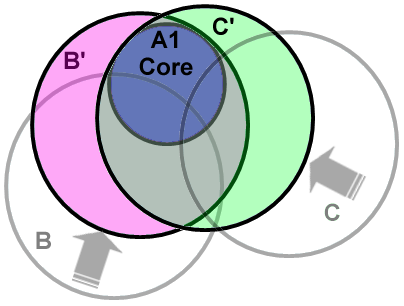 Figure 2: Core
assertions A1 pull B and C closer (becoming B' and C'), thus
reducing the likelihood of conflict.
Figure 2: Core
assertions A1 pull B and C closer (becoming B' and C'), thus
reducing the likelihood of conflict.
In effect, the "gravitational pull" of core assertion set A1 has caused
the assertion sets of AppB and AppC to move closer to each other.
Because B' and C' now have more assertions in common than B
and C
had, and perhaps also because their remaining assertions are now more
closely related to each other, the likelihood of compatibility is
increased (i.e., the likelihood of conflict is reduced).
@@ Add link to paper on
disambiguating, and explain what to do if AppB really needs B. @@
Admittedly, these clumping arguments are speculative and rely on a
sizeable element
of faith. It would be nice to quantitatively measure this
clumping
effect, if anyone can figure out a good way to do so.
[Are there more reasons I should
add, that help explain why URI declarations matter?]
Granularity of URI declarations
At one extreme, a URI declaration could assert everything that the URI
owner believes to be true about the associated resource (at least
within the URI owner's chosen model of the world), but this is likely
to limit the reusability of the URI by applications that need to model
some aspect of the resource differently. At the other extreme,
the URI declaration could contain no assertions whatsoever, in which
case the URI is not likely to be very useful, because its meaning will
not be anchored. Between these extremes, what declaration
granularity would best facilitate reuse of the URI?
At present, my best guess is that it is a trade-off between specifying
less in order to enable more flexible uses of the URI, thereby also
making the URI less useful on its own, versus specifying more in order
to make the URI more immediately useful, but thereby constraining its
reusability in conjunction with other, ancillary assertions. I
would be interested in others' thoughts on this. In some sense
Michel Dumontier's style of associating assertions with URIs amounts to
a practice of providing minimal URI declarations consisting of only
rdf:label and rdf:comment assertions -- see his email
and example protein page
-- except that as of this writing he is using rdfs:isDefinedBy instead
of rdfs:seeAlso to point to ancillary assertions.
Web architecture and implicit
URI declarations
How should URI declarations be indicated on the Web, and what should
the Web architecture say about them? At present, the Web
architecture does not explicitly specify any way to declare URIs.
The "following your nose" algorithm
[Editorial note: Somewhere a precise
definition of this algorithm should be provided. I didn't
bother to do so here, but it is needed. Perhaps the draft TAG
Finding on "Dereferencing HTTP URIs" would be a good place for
it. That document already has a cursory description of the
algorithm. -- DBooth]
Given a URI, it is very helpful to others if that URI's
declaration page can be readily located, using the URI as a starting
point:
Suggested practice P2:
URI owners should mint and support their URIs such that an attempt to
dereference a URI of a non-information resource will lead to a
URI declaration page for that URI, using one of the following
mechanisms:
- If the URI contains a fragment identifier, then the racine of the
URI
(i.e., the part before the #) should lead to a suitable URI
declaration page.
- If the URI does not contain a fragment identifier, then an
attempt to
dereference the URI should yield a 303-redirect that leads to a
suitable URI
declaration page.
Thus, http://dbooth.org/2007/moon/
303-redirects to its URI declaration page at http://dbooth.org/2007/moon/decl.html
. Notice that the declaration page is an information resource, so P2
does not apply to http://dbooth.org/2007/moon/decl.html
. This is further discussed in the next section.
Proposed rule for implicit URI
declarations
What act should be implicitly interpreted as URI declarations? I
propose that the Web architecture treat the act of serving a page
using either of the above two follow-your-nose mechanisms -- hash or
303 -- as a performative speech act of URI declaration:
Proposed
rule R1: Given a URI u,
if either of the follow-your-nose mechanisms described
above yields a
representation r, then, unless otherwise indicated, the conjunction of
assertions made in r represents an implicit URI declaration for u.
And the converse:
Proposed rulel R2:
Unless otherwise indicated (such as by rule R1 or by some explicit
indication), publication of assertions about a resource denoted by a
URI should not be construed as a performative speech act of declaring
that URI.
Note that rule R1 does not apply to http://dbooth.org/2007/moon/decl.html
, which denotes an information resource: rule R1 requires some
indirection, either by stripping a fragment identifier from the URI or
by a 303 redirect when the URI is dereferenced. This is
intentional, as it permits statements to be made about the document
that http://dbooth.org/2007/moon/decl.html
denotes without being required to accept the assertions contained in
that document. Similarly (and by rule R2) page http://dbooth.org/2007/moon/about.html
should not be interpreted as
a URI declaration page for http://dbooth.org/2007/moon/
, even though it makes statements about the resource denoted by http://dbooth.org/2007/moon/ .
Rule R1 should not necessarily be the only
way to declare a URI.
There could be other mechanisms also, particularly explicit mechanisms.
Rule R1 clearly has the first two components of a URI declaration, but
what is the performative speech act? First, publication of the
page -- regardless of the URI that leads to it -- represents the
utterance of the declaration. Second, the follow-your-nose
algorithm provides prima facie evidence that the declaration is authorized by the owner of the
originating URI. This is important because the domain name in the
URI of the declaration page could be quite different from the domain
name of the original resource URI. This act of publishing the
page in response to the
follow-your-nose algorithm from the original URI is what
distinguishes this performative speech act from other, normal speech.
This also means that if several URIs share the same URI declaration
page, examination of the URI declaration page via one of those URIs
will not necessarily indicate whether the other URIs are also being
declared. To avoid the inefficiency of having to dereference each
of
those URIs in order to determine their URI declarations, either
specialized URI prefixes can be defined (as described in "Converting New URI Schemes or
URN Sub-Schemes to HTTP"), or explicit URI declaration mechanisms
could be defined, such as the one proposed below.
Rule R1 also implies that, unless otherwise indicated, every assertion
in the page obtained should be considered a part of the URI
declaration and thus a core assertion. Therefore:
Suggested
practice P3: A URI declaration
page should not make assertions about the URI's
associated resource that are not intended to be a part of that URI's
declaration.
If a URI declaration page only contains URI declarations, how can other
parties find ancillary assertions about the associated resources?
Suggested
practice P4: A URI
declaration page
should provide links to suggested ancillary assertions about the
resources whose
URIs are declared by that page.
This does not mean that a URI owner should be responsible for providing
links to all other information about the associated resource. But
providing links to other known sources of information would be helpful
to others, and the URI declaration page is a logical starting
place to look for such links. It should be understood that
providing a link does not imply any particular endorsement.
Explicit URI declaration in RDF
One example of explicit URI declaration would be publication of a
specification that defines certain URIs, even if those URIs are not
dereferenceable. [Thanks to
Richard Cyganiak for suggesting this example. -- DBooth] This
raises the question of whether there is a recognized RDF way to express
URI declarations.
@@ Add something about
rdfs:isDefinedBy ?
http://www.w3.org/TR/2000/CR-rdf-schema-20000327/#s2.3.5 @@
I do not know of any explicit URI declaration predicate that has
already been defined for RDF, but
it would be easy to define one using named graphs:
If
g
is the URI of a named graph, and
u
is a URI, then the following
N3 statements
provide an explicit URI declaration for
u:
@prefix dbooth:
<http://t-d-b.org?http://dbooth.org/2007/uri-decl/#> .
dbooth:declares "u"^^xsd:anyURI
.
Note the quotes around URI u,
because in the declaration context it must be treated as a literal
string -- not a reference to
a resource -- so the domain and range of dbooth:declares would be:
dbooth:declares a rdfs:Property ;
rdfs:domain rdfg:Graph ;
rdfs:range xsd:anyURI .
where rdfg:Graph is the class of named graphs.
The dbooth:declares predicate has two of the three elements required
for a URI
declaration. A performative speech act (or evidence of one) is
still needed to complete the declaration.
Declaring URIs for Information Resources
The discussion above has focused on non-information resources.
How does URI declaration apply to information resources? Consider
a URI such as http://example/foo#bar having racine http://example/foo
, which dereferences to an HTTP 200 response containing some assertions
about the resource denoted by http://example/foo#bar
. The issue has a few factors:
- It would be helpful if the HTTP 200 response were architecturally
treated as authoritative, both because that would be more compatible
with the non-Semantic Web and because it is simple and objective.
- It seems important to be able to make statements about the
information resource denoted by http://example/foo without being
required to accept the assertions that it contains.
- It would be helpful to be able to declare additional properties
of an information resource, such as: all representations are the same,
they have a particular MD5 checksum, etc.
The first two factors seem to argue in favor of treating an HTTP 200
Okay response as an implicit, minimal declaration of the URI that was
dereferenced, not including assertions contained
in the representation that is returned. For a URI u, the URI
declaration would be equivalent to the N3 assertions:
<u> a
w:InformationResource .
<u> log:uri "u"^^xsd:anyURI .
where w:InformationResource
is the class of information resources and log:uri indicates
that the URI (string) on the right names the resource on the
left.
The third factor -- the desire to declare additional properties of an
information resource -- seems to argue against treating an HTTP 200
Okay response as an implicit URI declaration, but since there are other
ways that additional properties can be associated with an information
resource, this does not seem like a compelling argument. For
example, instead of merely placing a document at http://example/doc/bits
and publishing that URI another URI such as
http://example/doc/ir
can be minted such that when this second URI is dereferenced, it
303-redirects to a metadata URI such as
http://example/doc/metadata
and when that is dereferenced it returns a 200 OK with an URI
declaration such as:
<http://example/doc/ir> a w;InformationResource .
<http://example/doc/ir> :hasProvenance prov:whatever .
<http://example/doc/ir> :hasVersion "1.20" .
<http://example/doc/ir> :hasMd5Checksum "567990020087678940" .
<http://example/doc/ir> :hasBitsAt "http://example/doc/bits" .
And dereferencing http://example/doc/bits can yield a 200
OK with whatever data bits you were trying to denote. Note that http://example/doc/ir
would be the URI that you would want to publish -- not http://example/doc/bits
.
@@ Add explanation of how
<http://example/doc/ir> and <http://example/doc/bits> are
related and link to paper on
disambiguation. @@
According to the AWWW,
an information resource is independent of a URI: any number of
URIs could denote the same information
resource. Therefore the HTTP 200 Okay response by itself is not
enough to know whether some other URI might also name the same
information resource. Of course, the content returned with the
HTTP 200 Okay reponse might indicate whether there are other URIs for
that resource.
Acknowledgements
Thanks to Jeremy Carroll for early review comments.
Comments by all are invited. If I have missed a reference that I
should have included, please let me know.
03-Apr-2008: Tweaked prose
and added explanation of the URI-resource association as a two-step
mapping.
27-Mar-2008: Made the
domain and range of dbooth:declares explicit.
28-Feb-2008: Minor
editorial changes.
25-Feb-2008: Lots of
changes. Added sections on granularity, ancillary assertions, and
why it's important to distinguish URI declarations from ancillary
assertions. Added explanation of how a URI declaration relates to
resource identity. Rewrote the intro. Removed statement M2
about the moon being made of green cheese because it was causing
confusion.
6-Nov-2007: Added TOC
entry for "authoritative".
17-Aug-2007: Added section
on declaring URIs for information resources, and clarifications
suggested by Richard Cyganiak.
2-Aug-2007: Mentioned
evidence of a speech act. Added more
about "authoritative". Added link to PSI document. Added
mention of URI declaration creating a named graph.
1-Aug-2007: Misc clarifications per Pat Hayes' private email.
31-Jul-2007: Corrected the datatype of u (to xsd:anyURI); misc
clarifications.
30-Jul-2007: Added TOC, clarified speech act, misc minor fixes..
25-Jul-2007: Original draft.